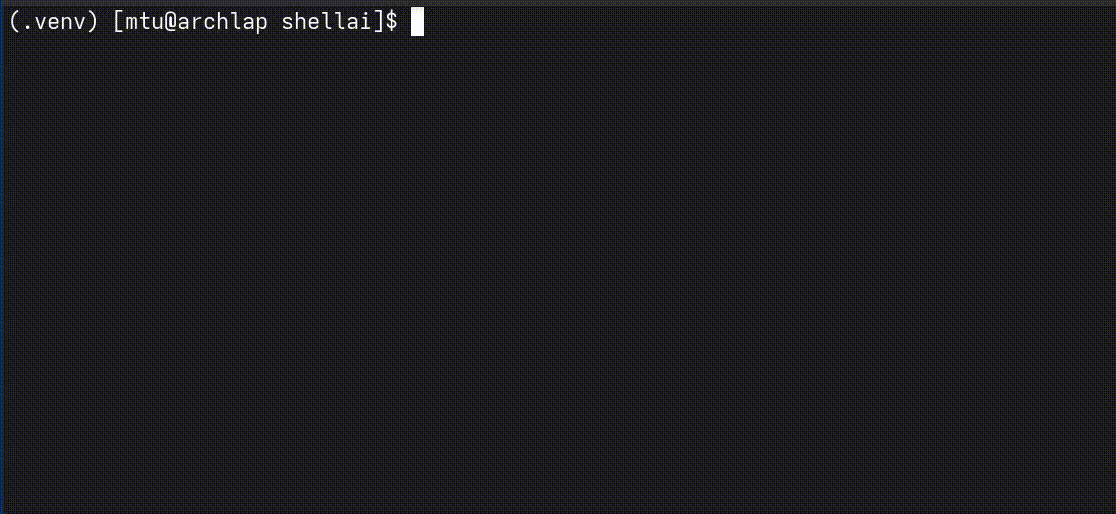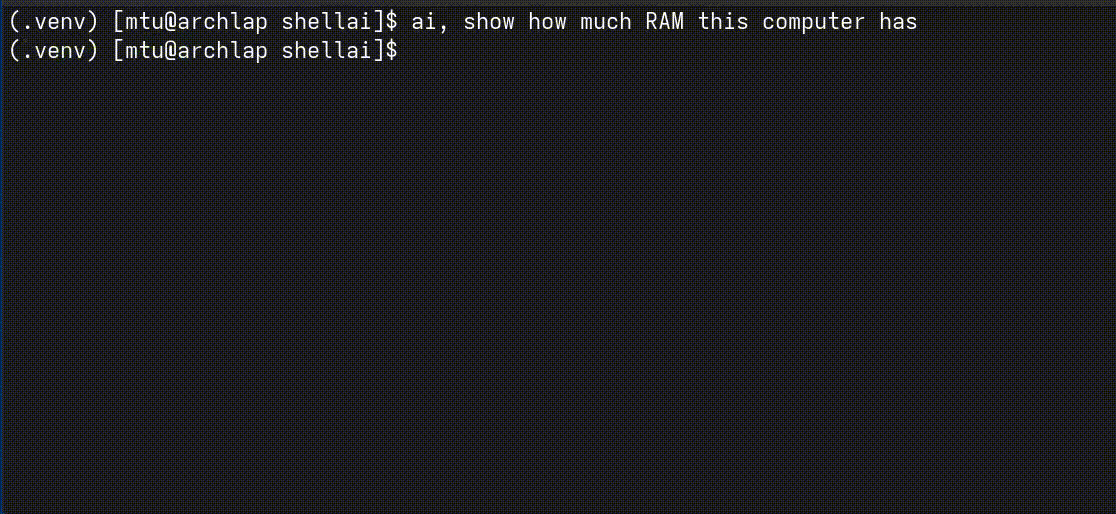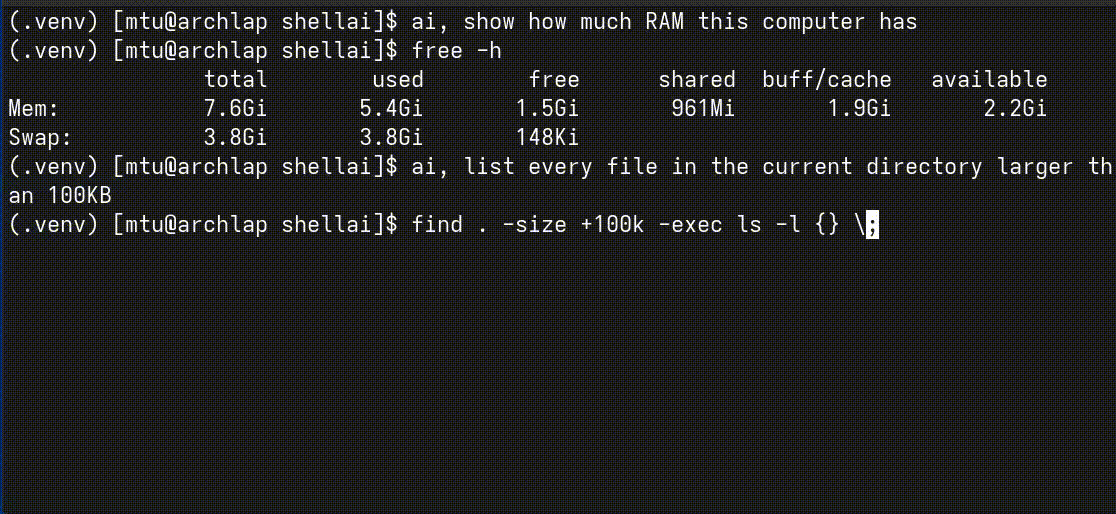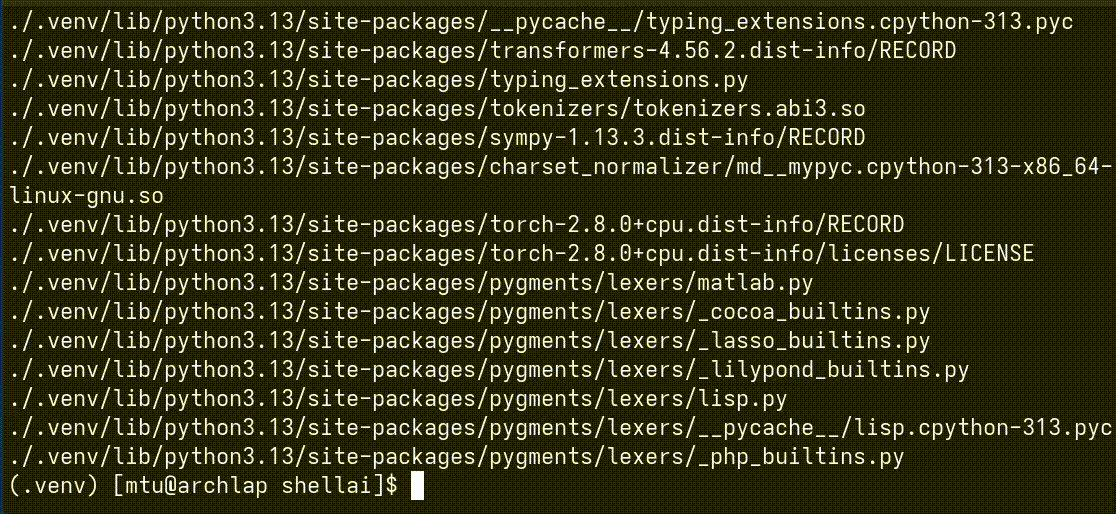
Shellai (pronounced shellay) is a command-line interface for getting AI assistance without network calls or a separate interface. It’s built around the idea that I should be able to, in my terminal, simply type ai, do this thing and have it generate the command for me and place it in my terminal for me to run. I shouldn’t need an internet connection to ship my request to a datacenter just to get some rudimentary help.
And now, I don’t!
Background
In September 2025, the power went out where I live. I had been doing some firmware analysis with the help of Gemini’s CLI, because trying to remember all the arguments and flags makes my brain sad. Unfortunately, no power meant no internet, which meant no AI assistance, so I set out on a run.
On that run, I tripped on a turtle and named him Shelly. That resulted in a rather long free association chain of thoughts to “shell ai”, which got me wondering why I hadn’t seen anyone use small, on-device LLMs to generate assistance in the terminal. I knew of “AI terminals” like Warp, but that still requires you to ship your requests off to a datacenter.
I ended up with the following list of requirements:
- Conversational prompting results in sensical and valid commands most of the time
- The recommended command must be made available in the TTY with minimal friction
- User must be able to edit the command before running it
- User must be able to hit enter and run the command without copy-pasting
- End-to-end latency should be under 10 seconds on my Surface Laptop 4
- 8 CPU i5-1235U
- 8GB RAM
The latency requirement is based on how long it took the Gemini CLI to execute a query:
[mtu@archlap etc]$ time gemini list every file in the current directory that contains the string "root" 2>/dev/null
I encountered permission errors while trying to search for "root" in `/etc`. Many files in this directory are protected. I cannot complete the request without read permissions to those files.
real 0m13.852s
user 0m3.330s
sys 0m0.378s
Model Selection and Fine-Tuning
My initial research uncovered that there’s a handful of small language models made available by the large AI labs. Here’s a table of them, with relevant features of each:
| Creator | Model Name | Parameters | Size (on disk) |
|---|---|---|---|
| Microsoft | Phi-3-mini-128k-instruct | 3.8B | 7GB |
| UC San Diego | TinyLlama | 1.1B | 2.2GB |
| gemma-3-270m-it | 270M | 600MB |
As you can see, Google’s Gemma-3 tiny model is by far the smallest. I figured I might as well start with it. On the publically available version, the model didn’t really perform well. Here’s the results of demo_shellai.py with Google’s model:
(.venv) [mtu@archlap shellai]$ python3 demo_shellai.py
Prompt: what are the files bigger than 1mb in the current directory
Generated command: ls -l
Prompt: find files modified in the last 24 hours
Generated command: find . -type f -mtime -1
Prompt: compress all .txt files into an archive
Generated command: \`\`\`bash
#!/bin mapping # Replace with your actual mapping
# Function to compress a file
compress_file() {
local file_path="$1"
local compressed_file_path="$2"
if [ -f "$file_path" ]; then
echo "File '$file_path' already exists."
return
else
# Attempt to open the file for compression
local file_opened = open(file_path, 'r')
if [[ -n "$file_opened" ]]; then
# Read the contents of the file
local content = file_opened.read()
local compressed_content = content.encode('utf-8')
local compressed_file = "$file_path"
compressed_file_path = "$compressed_file"
file_opened.close()
return
else
echo "Error opening file '$file_path': Could not open file."
return
fi
fi
}
# Function to extract a file
extract_file() {
local file_path="$1"
local file_name = "$file_path"
if
Prompt: show me the total disk usage of my home directory
Generated command: ls -l /home/your_username
Prompt: search for "EGG" in all ELF files in /usr/bin
Generated command: find /usr/bin -name "EGG" -type f -print0 | xargs sed -i 's/EGG/g'
One advantage of selecting such a small model, though, is that it’s pretty cost effective to fine-tune it for a specific use case. I was able to create a fine-tuned variant of the model, micrictor/gemma-3-270m-it-ft-bash, for the generation of bash commands based on English prompts, in only 4 hours on my desktop 4070-Super.
The fine-tuned model successfully reccommends a command line that seems much more reasonable:
(.venv) [mtu@archlap shellai]$ python3 demo_shellai.py
Prompt: what are the files bigger than 1mb in the current directory
Generated command: find . -size +10000k -print
Prompt: find files modified in the last 24 hours
Generated command: find . -mtime -1
Prompt: compress all .txt files into an archive
Generated command: bzip2 -9 *.txt
Prompt: show me the total disk usage of my home directory
Generated command: du -sh ~/
Prompt: search for "EGG" in all ELF files in /usr/bin
Generated command: find /usr/bin -name "*.elf" -exec grep '^EGG' {} \; -print
In my personal use of the tool, I’d estimate that it’s able to accomplish most tasks with >80% accuracy, though that’s far from a scientific measurement. More complex requests are, understandably, more likely to have errors. A larger model with similar fine-tuning would probably have better results, but then I almost certainly couldn’t meet my latency requirement.
Shell Prompt Injection
My last outstanding requirement was to make it so the generated command was “seamlessly” placed onto the user’s terminal.
Try 1 - TTY Writing
Since I am no stranger to shenanigans with TTYs, my first thought was that simply writing the command string to the PTY/TTY file descriptor for the parent terminal should be enough. After writing some code to find the TTY for the ancestor “bash” process of the running script, I had my first successful run - except for one problem.
While the contents of a string you write to a TTY is visible in the terminal, it isn’t “present” in the terminal in the same way you expect a command to be. This is easiest to show using two terminals and taking the following steps:
- Identify the TTY file descriptor for terminal 1
- In terminal 2, write a command to that file descriptor
- In terminal 1, try to run the “injected” command by hitting enter
- Observe that the “injected” command doesn’t run and isn’t present in history.

Try 2 - Foreign function calling using GDB
With TTY writing insufficient for my needs, I turned to process injection to read/write to the relevant buffers in the terminal process itself. After some research, I determine that Bash uses GNU readline to store and update it’s input buffer. Rather than try to directl read and write to the memory, I figured I’d use GDB’s call directive to just call the functions I needed by name. Those key functions were:
rl_replace_line- Replaces the current readline buffer with the suppliedchar *rl_forward_byte- Moves the cursor forward by the specified number of positionsrl_redisplay- Forces a redraw of the readline buffer so the injected command is visible
Once I had that working in interactive GDB sessions, I converted it to a set of GDB expressions that I could run without interaction on the command line, then used that as the implementation of my “tty” write.
def _write_to_tty(self, data):
"""
Use gdb to call readline functions in the parent shell process
This is an incredible hack, but it works!
"""
data = data.replace('"', r'\"').replace('\\', r'\\')
run = subprocess.run([
'gdb', '--batch',
'-p', str(self.parent_shell_pid),
'-ex', f'call (int)rl_replace_line("{data}", 0)',
'-ex', f'call (int)rl_forward_byte({len(data)}, 0)',
'-ex', 'call (void)rl_redisplay()',
'-ex', 'detach',
'-ex', 'quit'],
capture_output=True)
This did work, but it was very slow and came with a “non-Python” dependency on GDB. Since I wanted to be able to just pip install my tool, I needed to findT a PyPI supplied library to help me do the same.
Third and Final Try - Frida
When I asked in a Slack group I’m a part of, someone reccommended I use the Frida project’s Python bindings. I’d used Frida briefly for some embedded device security research, but had never used it’s Python bindings. I was pleasantly suprised to find that the frida PyPi package was not just the libraries, but also included all of the required runtime components for me to attach it to another process.
After some iteration, here’s the final Frida script I ended up with for Bash support. It dynamically resolves the address for some functions of interest, then exports wrapper functions that call them using correctly allocated memory.
var rl_replace_line = null;
var rl_forward_byte = null;
var rl_redisplay = null;
var describe_command = null;
var write = null;
try {
var exp = Process.getModuleByName("libc.so.6").getExportByName("write");
write = new NativeFunction(exp, 'int', ['int', 'pointer', 'int']);
Process.getModuleByName("bash").enumerateExports().forEach(function(exp) {
switch (exp.name) {
case 'rl_replace_line':
rl_replace_line = new NativeFunction(exp.address, 'int', ['pointer', 'int']);
break;
case 'rl_forward_byte':
rl_forward_byte = new NativeFunction(exp.address, 'int', ['int', 'int']);
break;
case 'rl_redisplay':
rl_redisplay = new NativeFunction(exp.address, 'void', []);
break;
case 'describe_command':
describe_command = new NativeFunction(exp.address, 'int', ['pointer', 'int']);
break;
default:
break;
}
});
// If Bash wasn't statically compiled, we also need to go hunting for the readline funcs in libreadline
if (!([rl_redisplay, rl_forward_byte, rl_replace_line].every(x => x !== null))) {
Process.enumerateModules().forEach(function(module) {
if (module.name.startsWith("libreadline")) {
rl_replace_line = new NativeFunction(module.getExportByName("rl_replace_line"), 'int', ['pointer', 'int']);
rl_forward_byte = new NativeFunction(module.getExportByName("rl_forward_byte"), 'int', ['int', 'int']);
rl_redisplay = new NativeFunction(module.getExportByName("rl_redisplay"), 'void', []);
}
});
}
} catch (e) {
console.log("Frida error: " + e.stack);
}
// checkCommand uses the describe_command function to check if a command is a valid callable type within the shell.
// Equivalent to `type -t <command>`
// This isn't perfect since a file isn't necessarily executable, but I'm using an injected javascript engine
// to directly call internal functions so nothing is perfect.
function checkCommand(command) {
if (describe_command === null) {
throw new Error("describe_command function not found");
}
var commandPtr = Memory.allocUtf8String(command);
// Capture stdout/stderr so we don't clutter the terminal
Interceptor.attach(write, {
onEnter: function (args) {
if (args[0].toInt32() === 1 || args[0].toInt32() === 2) {
args[1] = ptr("");
}
},
});
var result = describe_command(commandPtr, 8);
Interceptor.detachAll();
return result === 1; // Assuming 1 indicates a valid command.
}
// Function to write a string to the readline buffer
function writeToReadline(input) {
var inputPtr = Memory.allocUtf8String(input);
rl_replace_line(inputPtr, 0);
rl_forward_byte(input.length, 0);
rl_redisplay();
}
// Expose the writeToReadline function to be callable from Python
rpc.exports = {
writeToTty: writeToReadline,
checkCommand: checkCommand
};
If you read the above, you may have noticed the addition of a checkCommand method that I haven’t previously mentioned. When testing the tool, I noticed that sometimes the generated command would use a command or function that wasn’t valid in the current terminal. Since the model isn’t deterministic, re-running the tool would often generate a valid command on the second or third try.
At first, I considered calling out to man to trigger re-generation of the command, but that might not cover all valid commands. Instead, I found the function that implements the type builtin and call it. Since the call all running in the exact same shell the user is in, we can be sure that it will not have any false negatives.
Thanks to Frida, it was somewhat easy to add support for zsh. I just needed to find the right functions to call, plug them into a JavaScript file, and I was able to have my generated commands on ZSH too.
Future Opportunities
While I’m happy with where this wound up, I have a couple improvements I’d like to make over the coming months.
First, I want to address the cold start problem. Since I don’t have a persistent service running with the model loaded, I think a lot of the total runtime is spent just getting the model off disk and deserialized. By having some sort of hot-start server option, total runtime could get significantly reduced.
Second, I’d love it if this was a “multicall” script that routed calls to different models based on the command ran. While my laptop probably can’t handle a bigger model, on my MacBook Pro or desktop computer I could certainly see myself wanting to ask bigai, do this thing and have it call a larger/more capable model.
Third, I want to try to build a RAG system based on the locally available manpages. I think this would increase the ability of the tool to reccomend valid commands, both in terms of only using commands available on the user’s machine and using the proper syntax/flags. If the retrieval system supports natural language as an input via vector search or similar, it could even serve as a “next gen apropos”.
The longest shot goal I have would be to take advantage of LoRA adapters to implement the multicall feature I mentioned above to route user requests to the appropriate fine tunes of the same base model. This may require switching runtimes to vLLM or similar, but if my understanding is correct this approach might let me have multiple “expert” models without growing the required storage size unreasonably.
Conclusions / Lessons Learned
It was fun to build a semi-practical use of Frida that wasn’t focused on reverse engineering or vulnerability research. While my script certainly doesn’t use every feature Frida has, it’s the most complex Frida script I’ve ever written. I didn’t previously know about the Python bindings at all, and I thought the export API was pretty painless to use.
Even cooler was the impressive results I got from a “tiny” 270M parameter model. Maybe I just bought into the AI hype cycle too hard, but I assumed that such a small model would be incapable of generating useful results. Given that my laptop doesn’t have dramatically higher specifications than flagship smartphones, it also makes me hopeful that phone “smart assistance” like Siri will be able to serve at least some requests without calling the internet sooner rather than later.